

Entendiendo Random Forest: Un método de ensamblaje
El modelo de bosque aleatorio (RF), propuesto por primera vez por Tin Kam Ho en 1995, es una subclase de métodos de aprendizaje por conjuntos que se aplica a la clasificación y la regresión. Un método ensemble construye un conjunto de clasificadores -un grupo de árboles de decisión, en el caso de RF- y determina la etiqueta de cada instancia de datos tomando la media ponderada de los resultados de cada clasificador.
El algoritmo de aprendizaje utiliza el método "divide y vencerás" y reduce la varianza inherente a una única instancia del modelo mediante bootstrapping. Por lo tanto, "ensamblar" un grupo de clasificadores más débiles aumenta el rendimiento y el clasificador agregado resultante es un modelo más fuerte.
El bosque de decisión aleatorio es una modificación del bagging -agregación bootstrap, propuesta por Leo Breiman en 2001- que reúne una gran colección de árboles descorrelacionados sobre características seleccionadas al azar[1]. El ``número de árboles`` que componen el bosque está relacionado con la varianza del modelo, mientras que la ``profundidad del árbol`` o el ``número máximo de nodos que componen cada árbol`` está asociado con el sesgo irreducible presente en el modelo.

La RF presenta una serie de ventajas: Es muy rápido de implementar y ejecutar (se ejecuta eficazmente en grandes conjuntos de datos), uno de los algoritmos de aprendizaje más precisos y resistente al sobreajuste y a los valores atípicos[2]. El rendimiento de RF es similar pero más robusto que el de los árboles de decisión potenciados por gradiente (GBDT), otra subclase de métodos de conjunto de árboles. Además, como RF tiene menos hiperparámetros que GBDT, es más fácil de entrenar y ajustar. Como consecuencia, RF es muy popular y está soportado en varios lenguajes como R y SAS, y muchos paquetes en Python incluyendo scikit-learn y TensorFlow.
Estimador TensorForest: Compatibilidad y uso
TensorFlow ha incluido recientemente soporte para RF en la base de código contribuido - tf.contrib - a través de un módulo llamado tensor_forest (definido en https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/tensor_forest/__init__.py, nótese que el enlace a tensor_forest en el sitio web oficial de TensorFlow dirige al usuario a la rama con la versión más reciente y no a la rama master). Hay modificaciones significativas en tensor_forest en la versión 1.3.0 con respecto a la versión 1.2.0 y la estructura del código y los parámetros que se discutirán se ajustan a la versión 1.2.0.
Estructura e implementación de TensorForest
Los siguientes módulos deben ser importados para utilizar tensor_forest:
- from tensorflow.contrib.learn.python.learn import metric_spec
- from tensorflow.contrib.learn.python.learn.estimators import estimator
- from tensorflow.contrib.tensor_forest.client import eval_metrics
- from tensorflow.contrib.tensor_forest.client import random_forest
- from tensorflow.contrib.tensor_forest.python import tensor_forest
El paso inicial para ejecutar la RF en TensorFlow es construir el modelo. Para construir un estimador de RF, primero especifique los hiperparámetros de la RF de la siguiente manera:
hparams = tensor_forest.ForestHParams(num_classes=NUM_CLASSES,num_features=NUM_FEATURES,num_trees=NUM_TREES,max_nodes=MAX_NODES,min_split_samples=MIN_NODE_SIZE).fill()A continuación se describen cada uno de los hiperparámetros para el bosque tensorial mencionados anteriormente:
``num_classes``: El número de clases posibles para las etiquetas
``num_features``: El número de características. O bien ``num_splits_to_consider`` o bien ``num_features``.
según los colaboradores del código de tensor_forest, el modelo es más exacto
cuando ``num_splits_to_consider`` == ``num_features``[4].
``num_trees``: El número de árboles a construir para tomar la moda [para clasificación] o la media [para
regresión] de predicciones. Los árboles son "notoriamente ruidosos", por lo que "se benefician enormemente de la promediación"[5]. Cuantos más árboles compongan el bosque, menor será la varianza del modelo y, por tanto, más precisos serán los resultados. Sin embargo, existe un compromiso entre el rendimiento de los resultados y la velocidad de ejecución. Utilizar un gran número de árboles implica un mayor coste computacional y podría ralentizar significativamente el código. Normalmente, a partir de cierto número de árboles, el rendimiento del modelo se estanca y la mejora es insignificante[6].
Me gusta construir un bosque de cinco árboles para probar mi código con fines de depuración, uno de 100 árboles para tener una idea inicial de la exactitud, precisión, recuperación, auc, etc., y uno de 500 árboles para un modelo final que no necesite grandes ajustes. Por lo general, el uso de un modelo de 1.000 árboles no mejora significativamente el rendimiento de un bosque de 500 árboles.
*Por defecto: 100
Los dos hiperparámetros siguientes determinan la profundidad del árbol en un bosque. Limitar la profundidad del árbol no aporta ninguna ventaja adicional aparte de limitar el tiempo de cálculo y no se recomienda[7]. A mayor profundidad, menor sesgo. Cuando los árboles "crecen suficientemente profundos, [tienen] un sesgo relativamente bajo"[8].
``max_nodos``: El número máximo de nodos permitidos para cada árbol. Un número mayor de ``max_nodos``.
permite árboles más profundos.
*Predeterminado: 10000.
``min_split_samples``: "El número mínimo de muestras necesarias para dividir un nodo interno" según
SKlearn[9]. ``min_split_samples`` está relacionado con el tamaño mínimo de los nodos. Cuanto menor sea el número de muestras necesarias para dividir un nodo, más profundo puede crecer el árbol.
*Por defecto: 5

A continuación, determine el tipo de gráfico que se utilizará con RF; existen dos tipos de gráficos: El gráfico RF predeterminado [``RandomForestGraphs``] y el gráfico de pérdidas de entrenamiento [``TrainingLossForest``][11]. Para el anterior, el usuario puede aumentar la ponderación de las instancias positivas, normalmente para conjuntos de datos desequilibrados, pasando un vector de pesos.
[Nota: ``SKCompat`` es el wrapper de scikit-learn para TensorFlow[12]. ``model_dir`` debe ser un directorio donde se guarda la RF y el archivo de registro para la visualización tensorboard].
Si se selecciona el gráfico RF:
Para especificar un peso superior:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
parámetros,
graph_builder_class=clase del constructor de gráficos,
model_dir=MODEL_DIRECTORY,
pesos_nombre='pesos'))
O mantenga la ponderación por defecto de 1:1 de los puntos de datos positivos con respecto a los negativos:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
parámetros,
graph_builder_class=clase del constructor de gráficos,
model_dir=MODEL_DIRECTORY))
En el caso del bosque de pérdidas de entrenamiento, la pérdida de entrenamiento calculada a partir de la función de pérdida por defecto [``log_loss``] o una función de pérdida especificada se utiliza para ajustar los pesos[13].
Utiliza la función de pérdida por defecto ``log loss``:
clase_constructor_grafico = tensor_forest.TrainingLossForest
O especificar una función de pérdida que se utilizará en el gráfico de pérdidas de entrenamiento[14]:
from tensorflow.contrib.losses.python.losses import loss_ops
# Las funciones de pérdida válidas son:
#["diferencia_absoluta",
#"add_loss",
#"coseno_distancia",
#"compute_weighted_loss",
#"get_losses",
#"get_regularization_losses",
#"get_total_loss",
#"hinge_loss",
#"log_loss",
#"mean_pairwise_squared_error",
#"mean_squared_error",
#"sigmoid_cross_entropy",
#"softmax_cross_entropy",
#"sparse_softmax_cross_entropy"]
def pérdida_fn(val, pred):
_loss = loss_ops.hinge_lss(val, pred)
devolver _loss
def _build_graph(params, **kwargs):
return tensor_forest.TrainingLossForest(params,
loss_fn=_loss_fn, **kwargs)
graph_builder_class = _build_graph
Por último, construya el estimador RF con los hiperparámetros y el gráfico especificados anteriormente. est= estimator.SKCompat(random_forest.TensorForestEstimator(
hparams,
graph_builder_class=clase del constructor de gráficos,
model_dir=MODEL_DIRECTORY))
Una vez construida la RF, ajuste el modelo a los datos de entrenamiento mediante el método ``fit``.
Para gráfico RF con peso superior especificado*:
est.fit(x={‘x’:x_train, ‘weights’:train_weights},
y={‘y’:y_train},
batch_size=TAMAÑO_LOTE,
max_steps=MAX_STEPS)
*Nota: `weights` debe ser la misma clave que la pasada antes a ``TensorForestEstimator``.
``train_weights`` debe ser dimensión: (número de muestras, )
Para ponderación 1:1 por defecto o bosque de pérdida de formación:
est.fit(x=x_entrenamiento, y=y_entrenamiento
batch_size=TAMAÑO_LOTE,
max_steps=MAX_STEPS)
Para evaluar los resultados obtenidos por el modelo, identifique las métricas deseadas y páselas a la función ``evaluate``[15].
# otras métricas incluyen:
# true positives: tf.contrib.metrics.streaming_true_positives
# true negatives: tf.contrib.metrics.streaming_true_negatives
# falsos positivos: tf.contrib.metrics.streaming_false_positives
# falsos negativos: tf.contrib.metrics.streaming_false_negatives
# auc: tf.contrib.metrics.streaming_auc
# r2: eval_metrics.get_metric('r2')
# precisión: eval_metrics.get_metric('precisión')
# recall: eval_metrics.get_metric('recall')
metric = {‘accuracy’:metric_spec.MetricSpec(eval_metris.get_metric(‘accuracy’),
prediction_key=eval_metrics.get_prediction_key('exactitud')}
Si se da sobrepeso:
model_stats = est.score(x={‘x’:x_test, ‘weights’:test_weights},
y={‘y’:y_test},
batch_size=TAMAÑO_LOTE,
max_steps=MAX_STEPS,
métrica=metric)
para metric en model_stats:
print('%s: %s' % (métrica, model_stats[métrica])
Para la ponderación por defecto y el bosque de pérdidas de formación:
model_stats = est.score(x=x_prueba, y=y_prueba
batch_size=TAMAÑO_LOTE,
max_steps=MAX_STEPS,
métrica=metric)
para metric en model_stats:
print('%s: %0.4f' % (métrica, model_stats[métrica])
Para la etiqueta predicha y la probabilidad de cada clase para cada instancia de datos:
[Nota: ``predicted_prob`` y ``predicted_class`` son matrices numpy que conservan el orden de la entrada original].
Peso superior especificado:
predictions = dict(est.predict({‘x’:x_test, ‘weights’:test_weights}))
predicted_prob = predicciones[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predicciones[eval_metrics.INFERENCE_PRED_NAME]
Ponderación por defecto y bosque de pérdidas de formación:
predicciones = dict(est.predict(x=x_prueba))
predicted_prob = predicciones[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predicciones[eval_metrics.INFERENCE_PRED_NAME]
Por último, inicia tensorboard a través de terminal para visualizar el proceso de entrenamiento y el gráfico TensorFlow:
El directorio previamente pasado a ``model_dir`` debe ser dado.
$ tensorboard --logdir="./"
Abra http://localhost:6006/ o el enlace que aparece al ejecutar el comando anterior en el navegador para ver el tensorboard.

Comparación de TensorFlow y Scikit-Learn para modelos Random Forest
Actualmente, TensorFlow y scikit-learn son dos paquetes muy populares, cada uno con equipos de expertos que contribuyen y mantienen el código base, una miríada de tutoriales sobre el uso del código en línea y en papel, cobertura de la mayoría de los algoritmos de aprendizaje automático. Sin embargo, estos dos módulos no están orientados a las mismas tareas.
scikit-learn

Scikit se considera desde hace tiempo el "marco de aprendizaje automático general oficial de facto de Python"[17]. Ofrece una amplia base de código de algoritmos de aprendizaje automático que pertenecen a varias categorías: clasificación, regresión, clustering, reducción dimensional, etc[18]. Estos algoritmos bien empaquetados ofrecen a los usuarios un acceso inmediato a un análisis fácil y rápido del conjunto de datos. Por ejemplo, sklearn incluye un módulo RF que puede desplegarse en conjuntos de datos con sólo unas líneas:

Además de su facilidad de uso y su API estandarizada, scikit-learn está extraordinariamente bien documentado. Para cada biblioteca, hay páginas dedicadas no sólo a detallar la interfaz, los parámetros de entrada y el formato de salida, sino también a demostrar el uso del código con ejemplos cuidadosamente construidos. Usando de nuevo el módulo RF de sklearn como ilustración específica:
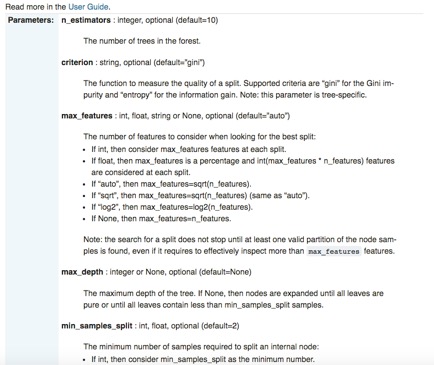

Aunque scikit-learn tiene numerosas ventajas destacadas, como la "brevedad sintáctica"[22], tiene una carencia particular: sklearn no es ni será compatible con GPU en un futuro próximo[23]. "El soporte de GPU introducirá muchas dependencias de software e introducirá problemas específicos de la plataforma. [...] Fuera de las redes neuronales, las GPU no juegan un papel importante en el aprendizaje automático hoy en día", según el sitio web oficial de sklearn. Por otro lado, el soporte nativo de TensorFlow para GPU es especialmente adecuado para el aprendizaje profundo.
TensorFlow
La potencia de TensorFlow brilla por su escalabilidad para "entrenar redes neuronales profundas en GPU[ y] posiblemente en clústeres de múltiples máquinas"[24], y por la gran libertad que concede a los usuarios a la hora de montar sus propios algoritmos de aprendizaje profundo. Los usuarios especifican no sólo qué tipo de modelo se utiliza, sino también cómo se implementa mediante el uso de las primitivas proporcionadas por el marco[25]. Definen exactamente "cómo [...] deben transformarse los datos [y] qué función de pérdida debe optimizar el modelo"[26]. Además, TensorFlow es muy flexible y portátil; está disponible en numerosas plataformas, como Ubuntu, Mac OS X, Windows, Android e iOS, y en una gran variedad de lenguajes, como Python, Java, C o Go[27]. Aunque parece especialmente atractivo por su escalabilidad e integrabilidad, la complicada estructura del código de TensorFlow, sus misteriosos mensajes de error y, en algunos casos, sus módulos mal documentados sobrecargan el proceso de depuración. Por lo tanto, utilizar TensorFlow para "la mayoría de las tareas prácticas de aprendizaje automático" es probablemente excesivo[28].
Presentación de Scikit Flow: un puente entre TensorFlow y Scikit-Learn
[https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/learn/python/learn]
Scikit flow (SKFlow) se presenta como una solución al dilema scikit-TensorFlow: aprovecha la "potencia de modelado de TensorFlow canalizando la brevedad sintáctica de scikit-learn"[29]. SKFlow es un proyecto oficial desarrollado por Google que proporciona una envoltura simplificada de alto nivel para TensorFlow[30].
Una red neuronal de tres capas con 10, 20 y 10 unidades ocultas respectivamente puede implementarse con cuatro líneas en SKFlow:

O crear un modelo personalizado con SKFlow con unas 10 líneas de código:
