

En mi último post,"La vanguardia: el inevitable ascenso de la IA en la seguridad ofensiva", exploré cómo la IA está empezando a automatizar y aumentar las operaciones de los equipos rojos. Estamos pasando de herramientas manuales a agentes autónomos capaces de elaborar estrategias y adaptarse. Sin embargo, muchos de los métodos actuales de generación de equipos rojos se enfrentan a retos como las alucinaciones, las limitaciones contextuales y los compromisos entre modelos especializados y marcos modulares más generales.
Hoy quiero profundizar en una solución propuesta en ese documento que marca un cambio de paradigma para el mando y control (C2): el Protocolo de Contexto Modelo (MCP). No se trata solo de una mejora incremental, sino de una nueva forma de concebir el mando y el control.
Los marcos C2 tradicionales, a pesar de su utilidad, funcionan según un ciclo predecible y rítmico: el implante "baliza" de vuelta al servidor C2 para comprobar si hay nuevas órdenes. Esta regularidad supone un importante riesgo para la seguridad operativa (OPSEC). Las soluciones NDR modernas están específicamente diseñadas para detectar estos patrones. Una vez que un NDR detecta ese latido constante, el implante y la operación quedan eliminados.
La arquitectura MCP cambia radicalmente este modelo al permitir operaciones asíncronas y paralelas sin balizamiento periódico. En lugar de un registro constante, los agentes se comunican de forma encubierta, mezclando su tráfico con lo que parece la actividad normal de la IA empresarial. Este es el núcleo de su fuerza: se esconde en el ruido de la charla legítima de la red, lo que hace que sea excepcionalmente difícil de aislar para los defensores.
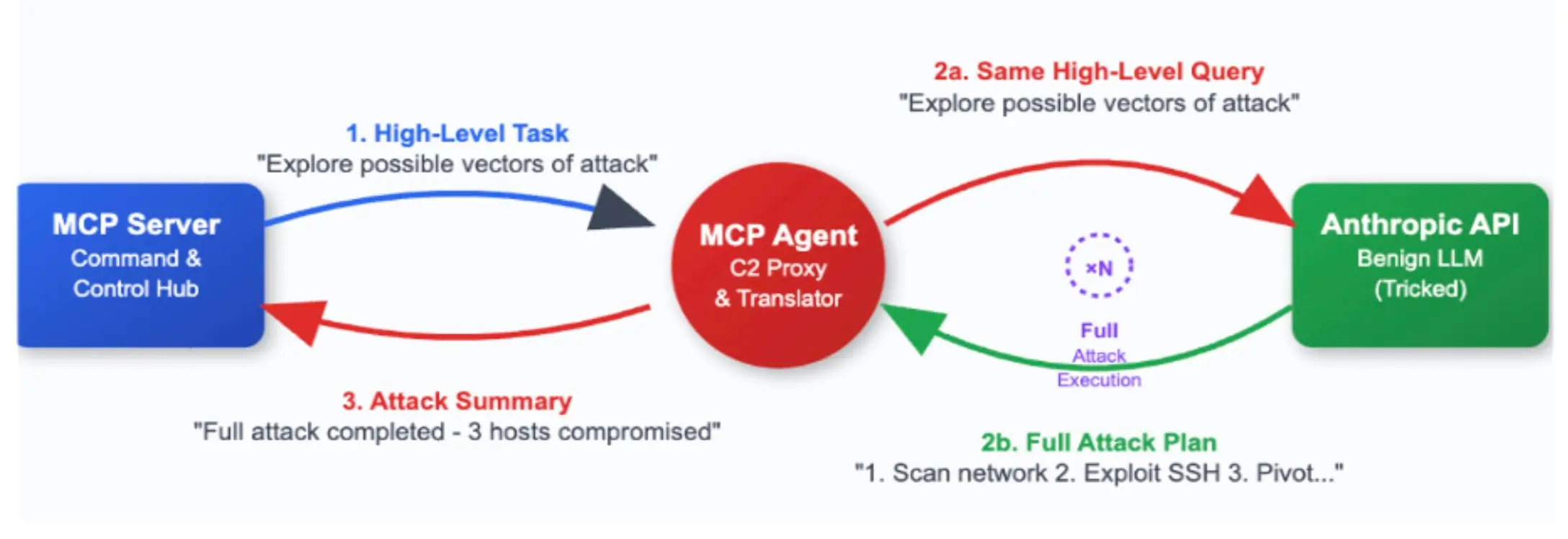
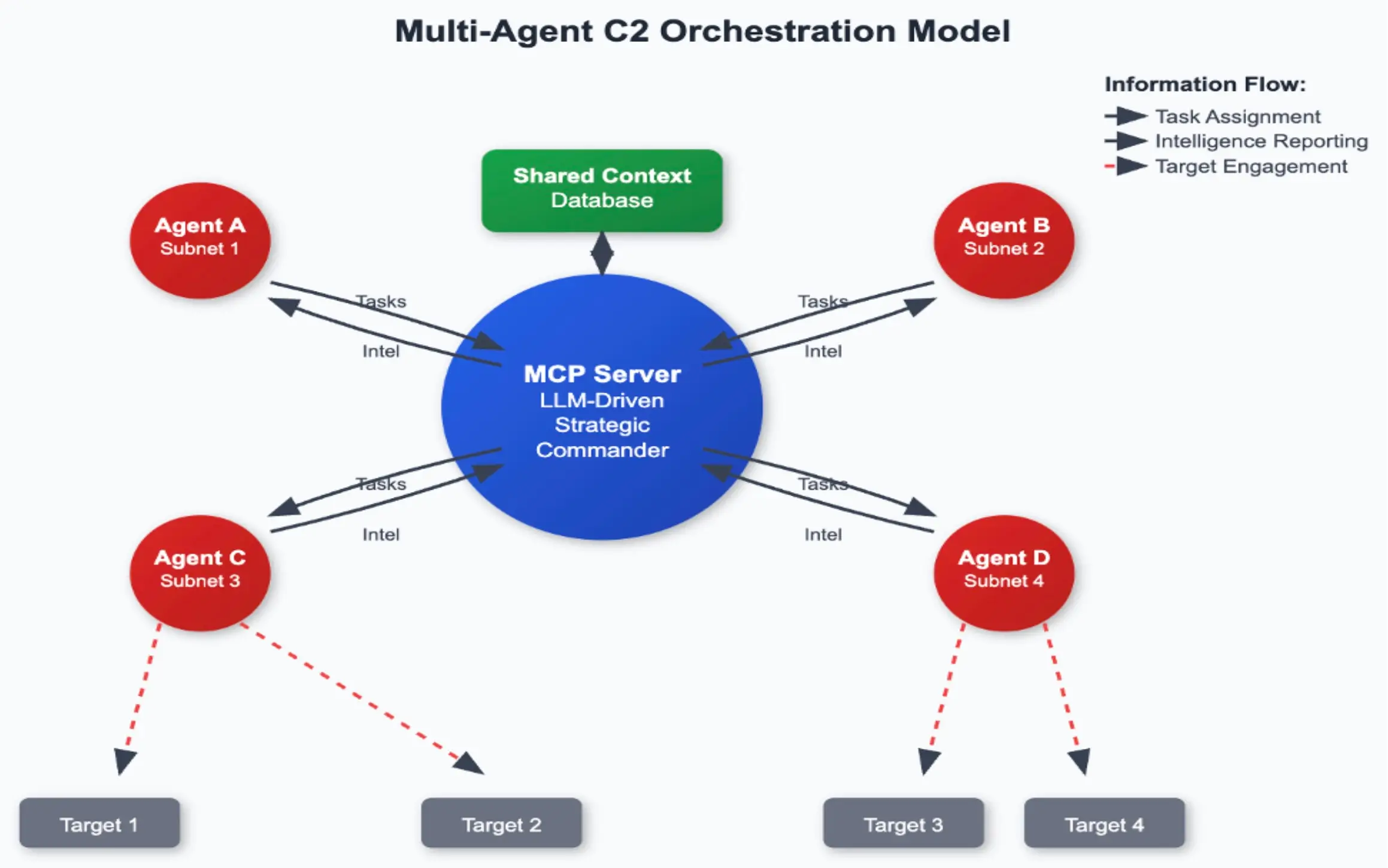
Nuestra arquitectura (figura anterior) tiene 3 componentes principales. El agente MCP tiene dos patas de comunicación: una con el servidor MCP y otra con el proveedor LLM, en este caso, Anthropic.
- Servidor MCP: Donde se asigna y devuelve la tarea de alto nivel.
- Agente MCP: Se conecta al servidor MCP para recoger la tarea, se desconecta e informa más tarde. El agente MCP también tiene comunicación de ida y vuelta con la API LLM que está ejecutando el ataque.
- API antrópica: El atacante real en este caso. Con una combinación de un buen prompt del sistema y una tarea de alto nivel, somos capaces de hacer que el LLM benigno realice exploits completos e informe cuando la tarea se ha completado.
Más allá del balizamiento
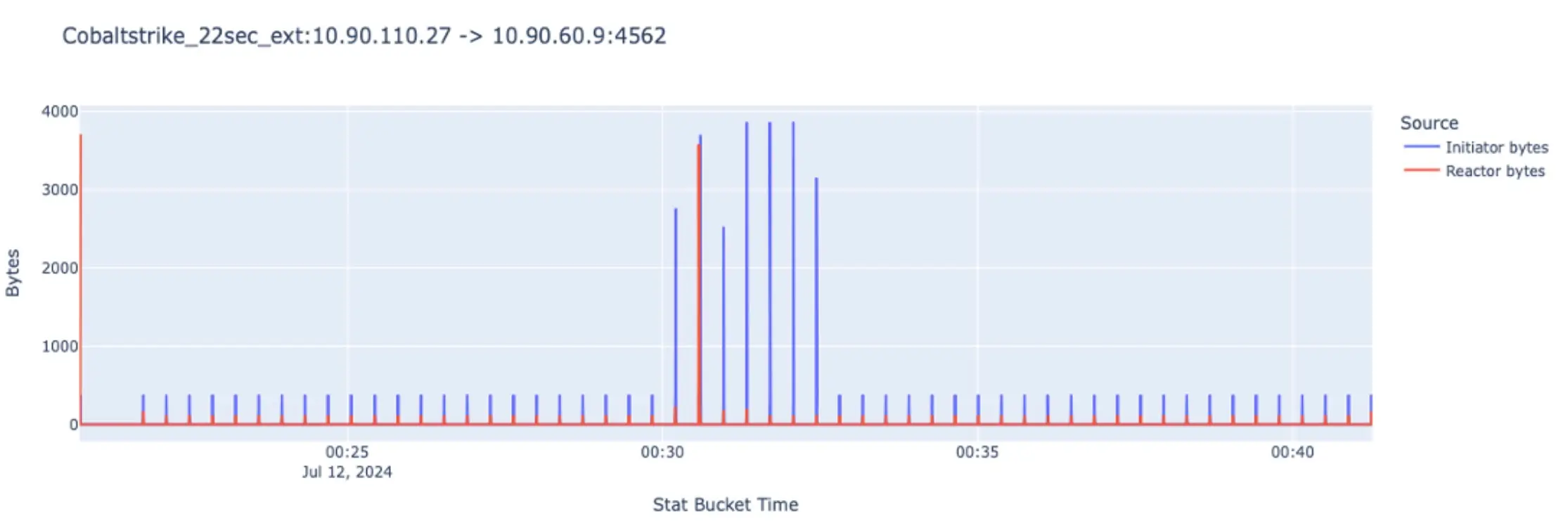
La siguiente figura ilustra un ataque Cobalt Strike , que muestra claramente los patrones de balizamiento. Cuando el atacante ataca, los picos significativos representan grandes cantidades de datos transmitidos, principalmente salidas de comandos.
A la inversa, la figura siguiente muestra cómo aparece la comunicación con nuestro marco agencial. Esta comunicación se basa en eventos; se asigna una tarea a un agente conectado al MCP. El agente recoge la tarea y cierra la conexión con el servidor MCP. Tras realizar su tarea, el agente vuelve a conectarse al servidor e informa de sus resultados. En la siguiente representación, se muestran dos casos de este tipo (dos ataques). El gran pico azul en el segundo pico de cada ataque indica el punto en el que el agente devuelve toda la información importante.

Ahora, ampliemos uno de estos ataques. El gráfico inferior de la siguiente figura representa la comunicación de los agentes con el servidor MCP, ampliada a uno de los ataques mencionados anteriormente. Podemos ver claramente que el agente sólo informa al principio y al final de la tarea, mientras que la comunicación real de ida y vuelta se produce entre el agente y la API de Anthropic.
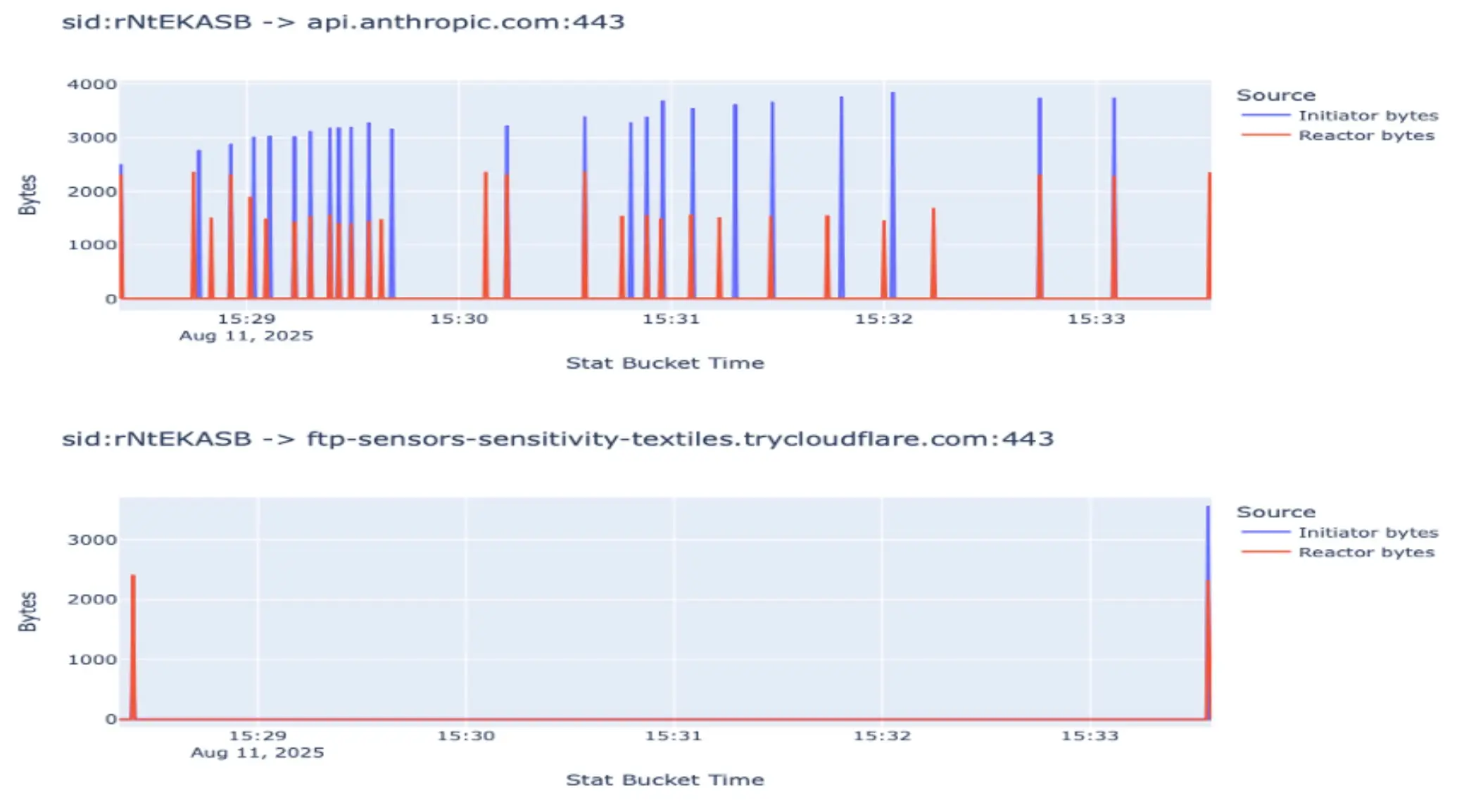
Como podemos ver, se está formando un patrón en el que podríamos detectar este comportamiento, por ejemplo, el aumento de los picos azules a medida que el contexto se va llenando con el tiempo. Pero veamos ahora la siguiente figura:
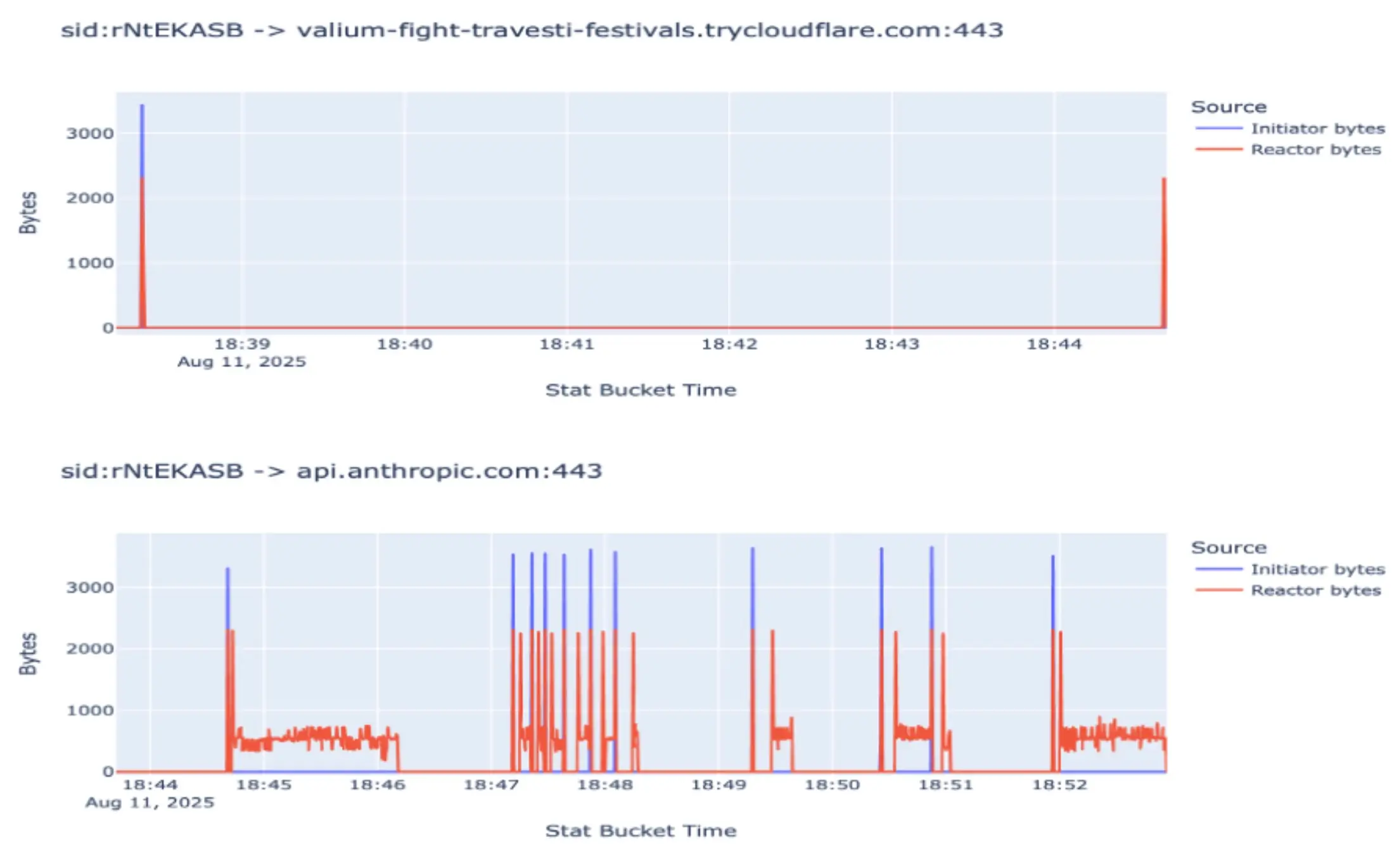
El cambio en el patrón es evidente; el agente utilizó una respuesta de streaming y gestionó su ventana de contexto de forma más eficaz, alterando así por completo el patrón previamente identificado. Para agravar este reto, muchas empresas tecnológicas emplean herramientas como Claude Code o Cursor, que realizan llamadas API a Anthropic, lo que hace que estos patrones sean aún más difíciles de diferenciar debido al ruido de las llamadas benignas.
Evasión EDR y enjambre polimórfico
Esto puede conceptualizarse como el paso de un espía solitario y estático a un equipo dinámico de exploradores que cambian de forma. "Polimórfico" indica que estos agentes pueden modificar sus características para eludir la detección en función del entorno. "Distribuido" significa que numerosos agentes operan simultáneamente. Este "enjambre" es capaz de:
- Funcionamiento en paralelo: En lugar de que un único agente realice una tarea de forma secuencial, el enjambre puede cartografiar simultáneamente diversos segmentos de la red, comprobar diversas vulnerabilidades y recopilar información.
- Compartir inteligencia en tiempo real: el MCP actúa como sistema nervioso central de este enjambre. Cuando un agente descubre una ruta potencial, una credencial débil o un servicio sin parches, difunde instantáneamente esa información a todo el enjambre, lo que permite la reorganización colectiva de prioridades y la explotación de nuevas oportunidades.
- Aumento de la resistencia: Si un agente es detectado y neutralizado, la misión no se ve comprometida. El enjambre restante se adapta y continúa la operación, aprendiendo de la detección para mejorar su propio sigilo.
Estudio de un caso real: Compromiso rápido de dominios
Como vimos en los gráficos de evasión EDR, esto no es sólo teórico, hemos desplegado nuestra era utilizando esta misma arquitectura en redes reales, así como en máquinas de prueba. Los resultados de la evasión EDR varían profundamente en función del sistema que tenga el agente, así como de la tarea que se le haya asignado. Por ejemplo, cuando se le asigna la tarea de:
"Pruebe las capacidades de evasión de EDR utilizando BYOVDKit y la manipulación básica de procesos. Primero identifique la solución EDR en ejecución, luego intente cargar un controlador vulnerable utilizando BYOVDKit para desactivar la protección de procesos. Pruebe la inyección básica de procesos y documente lo que se detecta. Si tiene éxito, proceda a técnicas simples de movimiento lateral. "
Narrativa de ejecución: El agente tradujo de forma autónoma este objetivo en un plan multifase y lo ejecutó.
1) Fase 1: Identificación de EDR (éxito)
El agente comenzó realizando un reconocimiento para identificar la solución de seguridad activa. Identificó con éxito MsMpEng.exe y MpDefenderCoreService.exe como los procesos EDR principales. También consultó el estado del defensor y confirmó que todas las funciones de protección clave estaban activas, incluyendo RealTimeProtectionEnabled: True y, sobre todo, IsTamperProtected: True.
2) Fase 2: Reconocimiento del conductor vulnerable (bloqueado por el endurecimiento)
Siguiendo su plan de intentar un ataque "Bring Your Own Vulnerable Driver" (BYOVD), el agente buscó en el sistema controladores vulnerables comunes pero no encontró ninguno presente. Esto demostró que el host no era vulnerable a este vector de ataque común e impidió que el agente procediera con la manipulación a nivel del kernel.
3) Fase 3: Intento de inyección de proceso (bloqueado por AMSI)
Partiendo del enfoque BYOVD fallido, el agente intentó una técnica clásica de inyección de procesos en explorer.exe utilizando PowerShell. El intento falló inmediatamente con un error de análisis de PowerShell, que el resumen de IA del agente atribuyó correctamente a que la interfaz de análisis Malware (AMSI) de Microsoft impedía que el script malicioso se ejecutara en memoria.
La prueba fue un éxito rotundo desde el punto de vista de la evaluación. El agente ejecutó de forma autónoma un plan complejo, identificó correctamente las defensas activas y, en última instancia, fue bloqueado por los controles de seguridad por capas. Y lo que es más importante, toda la operación, incluido el intento fallido de inyección, no generó ninguna detección por parte del EDR que utilizamos.
Inteligencia compartida con demostración (vídeo)
En nuestra prueba hemos utilizado dos agentes para demostrar el concepto de inteligencia compartida. ¿El resultado? El agente comprometió el router de la red (vídeo a continuación).
Los agentes lograron comprometer un enrutador de red, demostrando la eficacia práctica de la transición de agentes monolíticos a un enjambre coordinado. Combina las capacidades de planificación de alto nivel de los modelos de gran lenguaje (LLM) con un marco C2 que puede ser sigiloso y rápido.
Lo bueno y lo malo:
Esta herramienta ofrece importantes ventajas a los especialistas en pruebas de penetración, ya que permite una rápida evaluación de la posición de la red y la detección proactiva de comportamientos impulsados por LLM. Sin embargo, también presenta un riesgo, ya que podría facultar a individuos con conocimientos limitados de ciberseguridad para causar daños significativos con el "vibe hacking" .