

¿Recuerdas ese momento en el que alguien dice : "Vamos a conectar ChatGPT al SOC ", y todo el mundo asiente como si no pasara nada? Sí, este post trata de lo que ocurre después de ese momento.
Porque aunque suene genial, añadir GenAI a un SOC no es magia. Es complicado. Requiere muchos datos. Y si no se mide lo que realmente ocurre bajo el capó, se puede acabar automatizando la confusión.
Así que... decidimos medirlo.
GenAI en el SOC: buena idea, dura realidad
Empecemos por lo obvio: la IA está en todas partes en el ámbito de la seguridad en estos momentos.
En todas las presentaciones de SOC aparece una gran burbuja de "Asistente GenAI". Pero la verdadera prueba es cómo funcionan esos asistentes cuando se enfrentan a flujos de trabajo SOC reales.
El servidor Vectra MCP es el controlador aéreo de todos sus agentes de IA.
Conecta tu LLM (digamos ChatGPT o Claude) con tus herramientas de seguridad (¡y sus datos!) - en este caso, Vectra AI.
El MCP orquesta el enriquecimiento, la correlación, la contención y el contexto, permitiendo a su agente de IA interactuar directamente con las señales que importan en lugar de perderse en los cuadros de mando.
Y como queremos que todo el mundo aproveche y experimente estas capacidades, hemos lanzado 2 servidores MCP que le permiten conectar cualquier plataforma Vectra a sus flujos de trabajo de IA.
- ☁️ RUX - nuestro SaaS: http://github.com/vectra-ai-research/vectra-ai-mcp-server
- 🖥️ QUX - nuestra versión on-prem: http://github.com/vectra-ai-research/vectra-ai-mcp-server-qux
Así que, si has estado pensando: "Ojalá pudiera conectar mi LLM a mi pila de seguridad y ver qué pasa", ahora puedes hacerlo. Sin licencias ni acuerdos de confidencialidad, conéctalo y juega.
En Vectra AI, estamos convencidos de que GenAI + MCP cambiarán radicalmente el funcionamiento de los SOC.
No se trata de una idea de "algún día", ya está ocurriendo, y nos estamos asegurando de que los usuarios Vectra AI AI estén totalmente equipados para aprovechar este cambio.
También por eso pasamos mucho tiempo hablando con clientes, clientes potenciales y socios, para comprender la velocidad a la que avanzan estas tecnologías y lo que significa realmente "LLM-ready" en un SOC real.
Así que... decidimos medirlo.
Porque si GenAI va a remodelar las operaciones de seguridad, tenemos que estar absolutamente seguros de que nuestra plataforma, nuestros datos y nuestras integraciones MCP pueden conectarse a ese nuevo mundo sin problemas. Medir la eficacia no es un proyecto secundario: es la forma de preparar el SOC para el futuro.
No se trata de más datos, sino de mejores datos.
Seremos francos: GenAI sin buenos datos es como contratar a Sherlock Holmes y darle una venda en los ojos.
En Vectra AI, los datos son el elemento diferenciador. Dos cosas lo hacen especial:
- Detecciones basadas en IA: se basan en años de investigación sobre los comportamientos de los atacantes, no sobre anomalías. Están diseñadas para ser robustas, lo que significa que siguen siendo eficaces aunque los atacantes cambien de herramientas. Cada detección se centra en la intención y el comportamiento en lugar de en indicadores estáticos, lo que da a los equipos SOC la confianza de que lo que están viendo es real y relevante.
- Metadatos de red enriquecidos: telemetría de alto contexto que abarca entornos híbridos, estructurada y correlacionada para que sea legible por máquinas y se pueda actuar inmediatamente.
Ese es el tipo de datos que GenAI puede utilizar. Introdúcelos en un LLM y empezará a razonar como un analista experimentado. Aliméntalo con registros sin procesar y obtendrás una alucinación muy segura sobre DNS.
Entonces, ¿cómo se evalúa a un analista de IA?
Resulta que no puedes pedirle que "encuentre a los malos más rápido".
Hay que medir cómo razona. Y cuando tratas con un agente de IA con MCP, hay principalmente 3 cosas en las que puedes influir:
- El modelo (GPT-5, Claude, Deepseek, etc.)
- El estímulo (cómo le dices que actúe: tono, estructura, objetivos)
- El propio MCP (cómo se conecta a la pila de detección)
Cada uno de ellos puede mover la aguja del rendimiento.
Cambia ligeramente el mensaje y, de repente, tu "confiado" analista de IA olvidará cómo se escribe "PowerShell".
Cambia el modelo y la latencia se duplica.
Cambia la integración MCP, y la mitad de tu contexto desaparece.
Por eso hemos creado un banco de pruebas repetible: evaluación automatizada, escenarios SOC reales y una pizca de honestidad brutal.
El banco de pruebas (también conocido como "lo hemos probado")
En la primera prueba, las cosas fueron intencionadamente sencillas: tareas de nivel 1, razonamiento ligero (dos saltos como máximo) y ninguna coreografía multiagente sofisticada.
La pila tenía este aspecto:
- n8n para la creación rápida de prototipos y la automatización
- Servidor Vectra QUX MCP para acceder a los datos y manejar la plataforma.
- Un aviso mínimo del SOC (básicamente: "Eres un analista de IA. Ayuda. Si no sabes, dilo").
- Evaluación impulsada por un LLM Comparación de las respuestas esperadas con las reales
Pero no se trataba de un experimento de juguete. Pusimos a prueba 28 tareas SOC reales, de las que los analistas se enfrentan a diario. Cosas como:
- Listado de hosts en estado alto o crítico
- Extracción de detecciones para puntos finales específicos (piper-desktop, deacon-desktop, etc.)
- Comprobación de detecciones de comando y control vinculadas a IP o dominios
- Hallazgo de una filtración de más de 1 GB
- Etiquetado y eliminación de artefactos de host
- Búsqueda de cuentas en cuadrantes de riesgo "alto" o "crítico
- Búsqueda de cuentas "Admin" implicadas en operaciones EntraID
- Consulta de detecciones con huellas JA3 específicas
- Asignación de analistas a hosts o detecciones
Básicamente, todo lo que un analista SOC de nivel 1 o 2 tocaría en una ajetreada mañana de martes.
Cada carrera se puntuó en función de la corrección, la velocidad, el uso de fichas y la actividad de las herramientas, todo ello medido en una escala de 1 a 5.
¿Cómo es un buen agente GenAI?
Evaluar GenAI dentro de un SOC no consiste en ver qué modelo parece más inteligente. Se trata de la eficacia con la que piensa, actúa y aprende. Un buen agente de IA se comporta como un buen analista: no sólo obtiene la respuesta correcta, sino que lo hace de forma eficiente. Esto es lo que hay que buscar:
- Uso eficiente de los tokens. Cuantas menos palabras se necesiten para razonar, mejor. Los modelos prolijos desperdician espacio de cálculo y contexto.
- Llamadas inteligentes a las herramientas. Cuando un modelo llama a la misma herramienta una y otra vez, básicamente está diciendo "déjame intentarlo de nuevo". Los mejores saben cuándo y cómo utilizar una herramienta: mínimo ensayo y error, máxima precisión.
- Velocidad sin dejadez. La rapidez es buena, pero sólo si se mantiene la precisión. El modelo ideal equilibra la capacidad de respuesta con la profundidad de razonamiento.
En resumen: su mejor analista de IA no sólo habla, sino que piensa con eficacia.
Esto es lo que hemos encontrado:

Hechos destacados y conclusiones prácticas
- GPT-5 gana en precisión y profundidad de razonamiento, pero es lento y caro. Utilízalo cuando la precisión importe más que la velocidad.
- Claude Sonnet 4.5 ofrece el mejor equilibrio global: precisión, velocidad y eficiencia. Ideal para SOC de producción.
- Claude Haiku 4.5 es perfecto para el triaje rápido: rápido, barato y "suficientemente bueno" para las decisiones de primera línea.
- Deepseek 3.1 es el campeón de la relación calidad-precio: un rendimiento impresionante por una fracción del coste.
- Grok Code Fast 1 es para flujos de trabajo con muchas herramientas (automatización, enriquecimiento, etc.), pero vigile su factura de tokens.
- GPT-4.1... digamos que no está invitado a otro turno.
Y como todo buen artículo necesita gráficos, aquí tiene algunos:
Comparación de la puntuación de corrección

GPT-5 es técnicamente el ganador con 4,32/5, pero sinceramente... Claude Sonnet 4.5 y Deepseek 3.1 están básicamente empatados a 4,11 y probablemente no notes la diferencia. ¿El verdadero giro argumental? GPT 4.1 se hunde por completo con 2,61/5. Caray. No lo uses para temas de seguridad.
Tiempo de ejecución
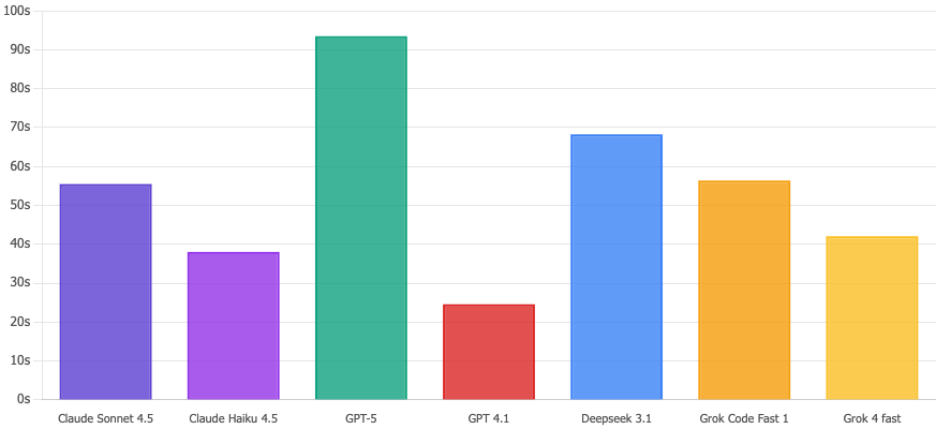
Claude Haiku 4.5 es volando a través de estas consultas en 38 segundos. Mientras tanto, GPT-5 da un tranquilo paseo de 93 segundos, literalmente 2,5 veces más lento. Cuando hay un incidente de seguridad potencial, esos segundos extra parecen eternos. Haiku lo consigue.
Matriz de propuestas de valor
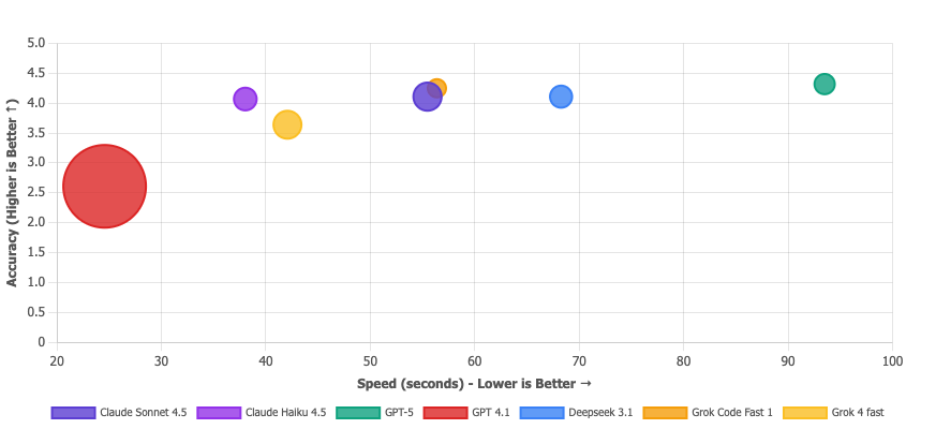
Burbuja más grande = menos fichas utilizadas. La burbuja de GPT 4.1 es enorme, pero eso no es un flex: es como decir "he acabado el examen superrápido" cuando lo has suspendido. Barato e incorrecto no es una propuesta de valor, es simplemente... incorrecto. Los modelos que realmente quieres están en la esquina superior derecha: Deepseek 3.1 (eficiente y preciso), Claude Sonnet 4.5 (una bestia equilibrada) y Grok Code Fast (sólido en todos los aspectos). La microburbuja de GPT-5 confirma que es la opción cara.
¿Qué hemos aprendido?
- La precisión no lo es todo. Un modelo ligeramente más preciso pero que tarda el doble y quema cinco veces más fichas puede no ser la mejor opción. En un SOC, la eficiencia y la escala forman parte de la precisión.
- El uso de herramientas es una ventana al razonamiento. "Si un LLM necesita diez llamadas a herramientas para responder a una pregunta sencilla, no está siendo minucioso: está perdido. Los modelos con mejores resultados no sólo obtuvieron la respuesta correcta, sino que lo hicieron de forma eficiente, utilizando una o dos consultas inteligentes a través del MCP. El uso de las herramientas no tiene que ver con la cantidad, sino con la rapidez con la que el modelo encuentra el camino correcto. No siempre hay que culpar al LLM. Un buen servidor MCP es esencial para una utilización óptima de las herramientas. Pero dejemos la evaluación del MCP para más adelante.
- El diseño de las preguntas está infravalorado. El más mínimo retoque en la redacción puede cambiar radicalmente los índices de precisión o alucinación. Hemos mantenido la pregunta al mínimo a propósito, como base para futuros ajustes, pero está claro que las pequeñas decisiones de diseño tienen grandes efectos.
Conclusión (y un poco de realidad)
La cuestión es que no se trata de saber qué modelo gana un concurso de belleza. Claro que el GPT-5 puede superar al Claude en una u otra métrica, pero eso no es lo importante.
La verdadera lección es que la evaluación de su agente de IA no es opcional.
Si vas a confiar en GenAI dentro de tu SOC -para triar alertas, resumir incidentes o incluso llamar a acciones de contención-, entonces necesitas saber cómo se comporta, dónde falla y cómo evoluciona con el tiempo.
La IA sin evaluación no es más que automatización sin responsabilidad.
E igualmente importante: sus herramientas de seguridad deben hablar LLM.
Eso significa datos estructurados, API limpias y un contexto legible por las máquinas, no encerrado en cuadros de mando o silos de proveedores. El modelo más avanzado del mundo no puede razonar si se alimenta de telemetría medio rota.
Por eso, en Vectra AI estamos obsesionados con asegurarnos de que nuestra plataforma, y nuestro servidor MCP, estén preparados para LLM por diseño. Las señales que producimos no solo están pensadas para los humanos, sino también para que las consuman las máquinas, los agentes de IA que pueden razonar, enriquecer y actuar.
Porque en la próxima ola de operaciones de seguridad, no basta con utilizar IA: todo su ecosistema tiene que ser compatible con la IA.
El SOC del futuro no sólo funciona con IA. Está medido por IA, conectado por IA y preparado para la IA.