

Definir la inteligencia artificial (IA) es una tarea compleja, a menudo sujeta a perspectivas cambiantes. Las definiciones basadas en objetivos o tareas pueden cambiar a medida que avanza la tecnología. Por ejemplo, los sistemas de juego de ajedrez fueron uno de los focos de las primeras investigaciones sobre IA hasta que Deep Blue, de IBM, derrotó al gran maestro Gary Kasparov en 1997, con lo que la percepción del ajedrez pasó de requerir inteligencia a técnicas de fuerza bruta.
Por otra parte, las definiciones de IA que tienden a centrarse en motivos procedimentales o estructurales a menudo se empantanan en cuestiones filosóficas fundamentalmente irresolubles sobre la mente, la emergencia y la conciencia. Estas definiciones no nos ayudan a comprender cómo construir sistemas inteligentes ni a describir los sistemas que ya hemos creado.
El Test de Turing: una medida de la inteligencia de las máquinas

El test de Turing, a menudo considerado una prueba de la inteligencia de las máquinas, fue la forma que tuvo Alan Turing de eludir la cuestión de la inteligencia. Subrayaba la vaguedad semántica de la inteligencia y se centraba en lo que las máquinas pueden hacer en lugar de en cómo las etiquetamos.
"La pregunta original '¿Pueden pensar las máquinas? creo que carece demasiado de sentido como para merecer discusión. Sin embargo, creo que a finales de siglo, el uso de las palabras y la opinión general educada habrán cambiado tanto que se podrá hablar de máquinas que piensan sin esperar ser contradicho." - Alan Turing
Al final, se trata de una cuestión de convención, no muy diferente de debatir si debemos referirnos a los submarinos como nadadores o a los aviones como voladores. Para Turing, lo que realmente importaba eran los límites de lo que las máquinas son capaces de hacer, no cómo nos referimos a esas capacidades.
Medición del pensamiento humano en la IA
Por eso, si se quiere saber si las máquinas pueden pensar como los humanos, lo mejor es medir hasta qué punto la máquina puede engañar a otras personas haciéndoles creer que piensa como los humanos. Siguiendo a Turing y la definición proporcionada por los organizadores del primer taller sobre IA en 1956, sostenemos de forma similar que "cada aspecto del aprendizaje o cualquier otra característica de la inteligencia puede, en principio, describirse con tanta precisión que se puede hacer que una máquina lo simule."
Para lograr un rendimiento o comportamiento similar al humano en cualquier tarea, la IA debe ser capaz de simularlo con un notable nivel de precisión. El famoso test de Turing se diseñó para evaluar esta capacidad mediante la valoración de la eficacia con la que un ordenador o máquina podía engañar a un observador a través de una conversación no estructurada. La prueba original de Turing exigía incluso que la máquina representara de forma convincente una identidad femenina.
Evaluación de la comprensión humana de la IA
En los últimos años, los avances significativos en las técnicas de aprendizaje automático, junto con la abundancia de amplios datos de entrenamiento, han permitido a los algoritmos entablar conversaciones con un mínimo de comprensión. Además, tácticas aparentemente insignificantes, como incorporar deliberadamente faltas de ortografía y errores gramaticales al azar, contribuyen a que los algoritmos sean cada vez más persuasivos como humanos virtuales, a pesar de carecer de auténtica inteligencia.
Los nuevos enfoques para evaluar la comprensión a nivel humano, como los esquemas de Winograd, proponen interrogar a una máquina sobre su conocimiento del mundo, los usos de los objetos y las asequibilidades que suelen entender los humanos. Por ejemplo, si preguntáramos: "¿Por qué no cabe el trofeo en la estantería? Porque era demasiado grande. ¿Qué era demasiado grande?", cualquier persona averiguaría inmediatamente que el trofeo era el elemento demasiado grande. Por el contrario, con una simple sustitución: "El trofeo no cabía en la estantería porque era demasiado pequeño. ¿Qué era demasiado pequeño?", indagamos sobre la inadecuación del tamaño.
En este escenario, la respuesta está inequívocamente en la estantería. Esta prueba, de gran precisión, ahonda en las profundidades del conocimiento de las máquinas sobre el mundo. La simple extracción de datos por sí sola no puede dar una respuesta. Esta definición requiere que una IA tenga la capacidad de emular cualquier faceta del comportamiento humano, lo que establece una distinción significativa con respecto a los sistemas de IA diseñados específicamente para demostrar inteligencia en tareas concretas.
Diferenciar los tipos de IA y sus métodos de aprendizaje
Inteligencia General Artificial (AGI)
La Inteligencia Artificial General (IAG), comúnmente conocida como IA General, es el concepto que se discute con más frecuencia cuando se habla de IA. Abarca los sistemas que evocan nociones futuristas de "señores robots" gobernando el mundo, capturando nuestra imaginación colectiva a través de la literatura y el cine.
IA específica o aplicada
La mayor parte de la investigación en este campo se centra en sistemas de IA específicos o aplicados. Estos abarcan una amplia gama de aplicaciones, desde los sistemas de reconocimiento de voz y visión por ordenador de Google y Facebook hasta la IA de ciberseguridad desarrollada por nuestro equipo en Vectra AI.
Los sistemas aplicados suelen utilizar una amplia gama de algoritmos. La mayoría de los algoritmos están diseñados para aprender y evolucionar con el tiempo, optimizando su rendimiento a medida que acceden a nuevos datos. La capacidad de adaptarse y aprender en respuesta a nuevas entradas define el campo del aprendizaje automático. Sin embargo, es importante señalar que no todos los sistemas de IA requieren esta capacidad. Algunos sistemas de IA pueden funcionar con algoritmos que no dependen del aprendizaje, como la estrategia de Deep Blue para jugar al ajedrez.
Sin embargo, estas ocurrencias suelen limitarse a entornos y espacios de problemas bien definidos. De hecho, los sistemas expertos, uno de los pilares de la IA clásica (GOFAI), se basan en gran medida en conocimientos preprogramados y basados en reglas en lugar de en el aprendizaje. Se cree que la AGI, junto con la mayoría de las tareas de IA comúnmente aplicadas, necesitan alguna forma de aprendizaje automático.

El papel de Machine Learning
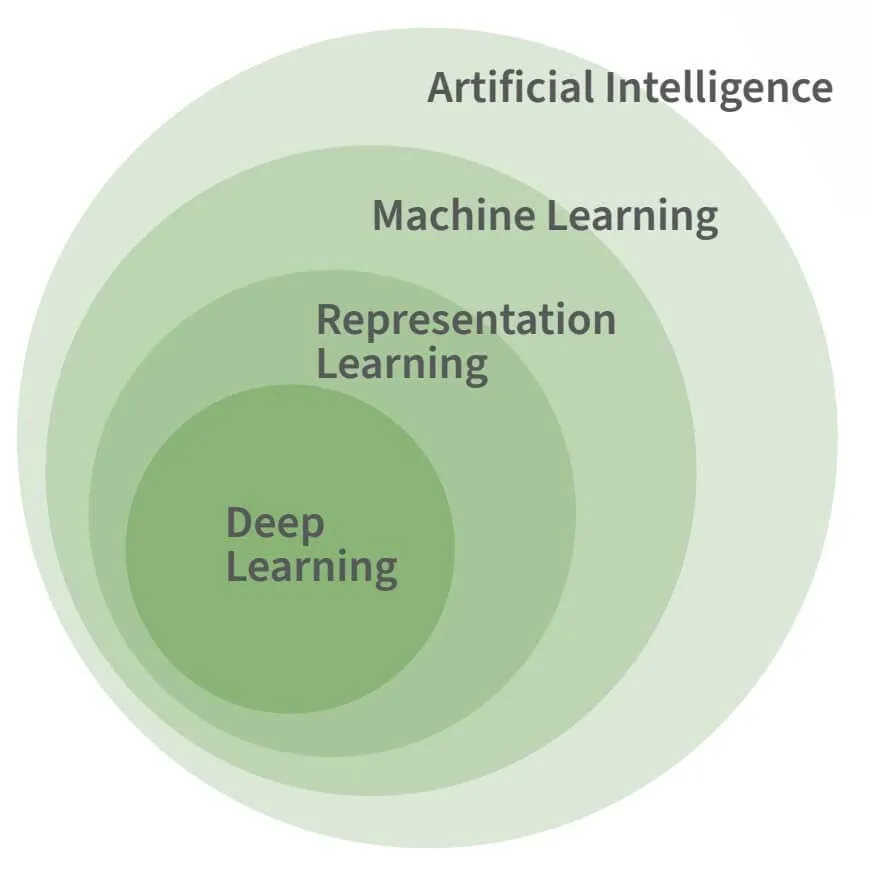
La figura anterior muestra la relación entre IA, aprendizaje automático y aprendizaje profundo. El aprendizaje profundo es una forma específica de aprendizaje automático, y aunque se supone que el aprendizaje automático es necesario para la mayoría de las tareas avanzadas de IA, no es por sí solo una característica necesaria o definitoria de la IA.
El aprendizaje automático es necesario para imitar las facetas fundamentales de la inteligencia humana, más que sus complejidades. Tomemos, por ejemplo, el programa de IA Logic Theorist desarrollado por Allen Newell y Herbert Simon en 1955. Consiguió demostrar 38 de los 52 teoremas iniciales de Principia Mathematica sin necesidad de aprendizaje.
IA, Machine Learning y Deep Learning: ¿Cuál es la diferencia?
La inteligencia artificial (IA), el aprendizaje automático (AM) y el aprendizaje profundo (AD) suelen confundirse, pero cada uno tiene su propio significado. Si entendemos el alcance de estos términos, podremos comprender mejor las herramientas que aprovechan la IA.
Inteligencia Artificial (IA)
La IA es un término amplio que engloba los sistemas capaces de automatizar el razonamiento y aproximarse a la mente humana. Incluye subdisciplinas como el ML, la RL y la DL. La IA puede referirse tanto a los sistemas que siguen reglas explícitamente programadas como a los que obtienen conocimientos de forma autónoma a partir de datos. Esta última forma, que aprende de los datos, es la base de tecnologías como los coches autónomos y los asistentes virtuales.
Machine Learning (ML)
El ML es una subdisciplina de la IA en la que las acciones del sistema se aprenden a partir de los datos en lugar de ser dictadas explícitamente por los humanos. Estos sistemas pueden procesar cantidades ingentes de datos para aprender a representar y responder a nuevas instancias de datos de forma óptima.
Vídeo: Machine Learning Fundamentos para profesionales de la ciberseguridad
Representation Learning (RL)
La RL, que a menudo se pasa por alto, es crucial para muchas tecnologías de IA que se utilizan hoy en día. Consiste en aprender representaciones abstractas a partir de datos. Por ejemplo, transformar imágenes en listas de números de longitud coherente que capten la esencia de las imágenes originales. Esta abstracción permite a los sistemas posteriores procesar mejor nuevos tipos de datos.
Deep Learning (DL)
La DL se basa en el ML y la RL para descubrir jerarquías de abstracciones que representan las entradas de forma más compleja. Inspirados en el cerebro humano, los modelos de DL utilizan capas de neuronas con pesos sinápticos adaptables. Las capas más profundas de la red aprenden nuevas representaciones abstractas que simplifican tareas como la categorización de imágenes y la traducción de textos. Es importante señalar que, aunque la DL es eficaz para resolver ciertos problemas complejos, no es una solución única para automatizar la inteligencia.
Referencia: "Deep Learning," Goodfellow, Bengio & Courville (2016)
Técnicas de aprendizaje en IA
Mucho más difícil es la tarea de crear programas que reconozcan el habla o encuentren objetos en imágenes, a pesar de que los humanos las resuelven con relativa facilidad. Esta dificultad se deriva del hecho de que, aunque para los humanos es intuitivamente sencillo, no podemos describir un conjunto simple de reglas que permitan elegir fonemas, letras y palabras a partir de datos acústicos. Es la misma razón por la que no podemos definir fácilmente el conjunto de rasgos de píxeles que distinguen una cara de otra.

La figura de la derecha, tomada del artículo de Oliver Selfridge de 1955, Pattern Recognition and Modern Computers, muestra las mismas entradas y puede dar lugar a diferentes salidas, dependiendo del contexto. Abajo, la H de THE y la A de CAT son conjuntos de píxeles idénticos, pero su interpretación como una H o una A depende de las letras circundantes más que de las propias letras.
Por esta razón, ha habido más éxito cuando se permite a las máquinas aprender a resolver problemas en lugar de intentar predefinir cómo es una solución.
Los algoritmos de ML tienen la capacidad de clasificar los datos en diferentes categorías. Los dos tipos principales de aprendizaje, supervisado y no supervisado, desempeñan un papel importante en esta capacidad.
Aprendizaje supervisado
El aprendizaje supervisado enseña a un modelo con datos etiquetados, lo que le permite predecir etiquetas para nuevos datos. Por ejemplo, un modelo expuesto a imágenes de gatos y perros puede clasificar nuevas imágenes. A pesar de necesitar datos de entrenamiento etiquetados, etiqueta eficazmente los nuevos puntos de datos.

Aprendizaje no supervisado
Por otro lado, el aprendizaje no supervisado trabaja con datos no etiquetados. Estos modelos aprenden patrones dentro de los datos y pueden determinar dónde encajan los nuevos datos en esos patrones. El aprendizaje no supervisado no requiere formación previa y es excelente para identificar anomalías, pero tiene dificultades para asignarles etiquetas.
Ambos enfoques ofrecen una gama de algoritmos de aprendizaje, en constante expansión a medida que los investigadores desarrollan otros nuevos. Los algoritmos también pueden combinarse para crear sistemas más complejos. Saber qué algoritmo utilizar para un problema concreto es un reto para los científicos de datos. ¿Existe un algoritmo superior que pueda resolver cualquier problema?

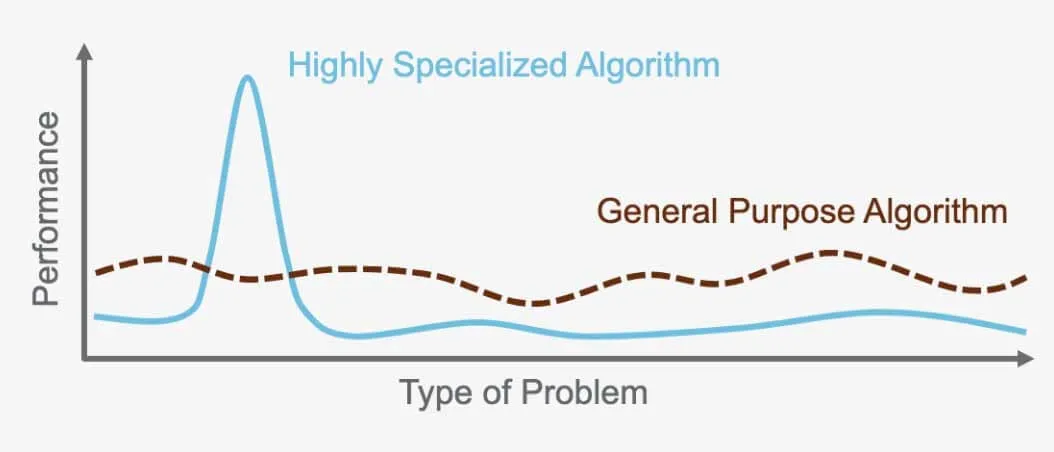
Teorema 'No Free Lunch ': no existe ningún algoritmo universal
El "TeoremaNo Free Lunch " afirma que no existe un algoritmo perfecto que supere a todos los demás para todos los problemas. Por el contrario, cada problema requiere un algoritmo especializado que se adapte a sus necesidades específicas. Por eso existen tantos algoritmos diferentes. Por ejemplo, una red neuronal supervisada es ideal para ciertos problemas, mientras que la agrupación jerárquica no supervisada funciona mejor para otros. Es importante elegir el algoritmo adecuado para la tarea en cuestión, ya que cada uno está diseñado para optimizar el rendimiento en función del problema y los datos que se utilicen.
Por ejemplo, el algoritmo utilizado para el reconocimiento de imágenes en los coches autoconducidos no puede utilizarse para traducir entre idiomas. Cada algoritmo sirve para un propósito específico y está optimizado para el problema para el que fue creado y los datos con los que opera.
Selección del algoritmo adecuado en la ciencia de datos
Elegir el algoritmo adecuado como científico de datos es una mezcla de arte y ciencia. Teniendo en cuenta el planteamiento del problema y comprendiendo a fondo los datos, el científico de datos puede orientarse en la dirección correcta. Es crucial reconocer que tomar la decisión equivocada puede conducir no sólo a resultados subóptimos, sino completamente inexactos. Eche un vistazo al siguiente ejemplo:
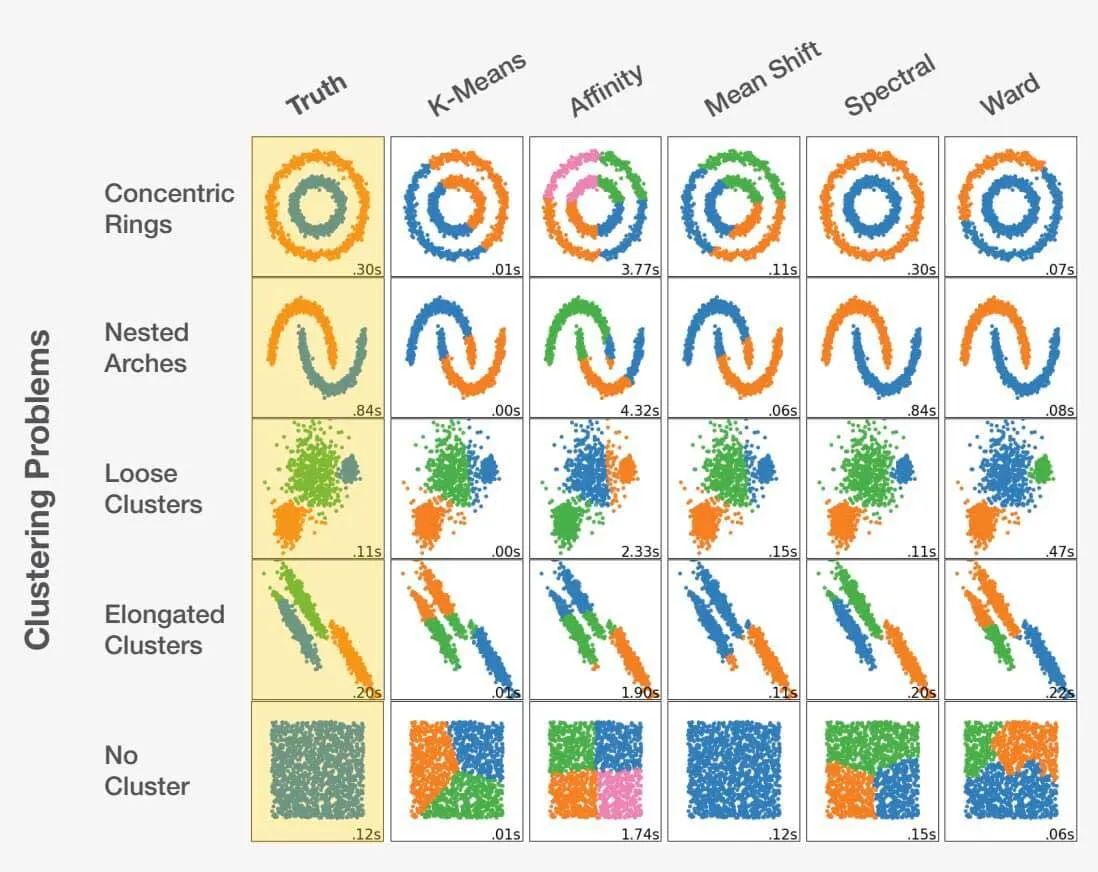
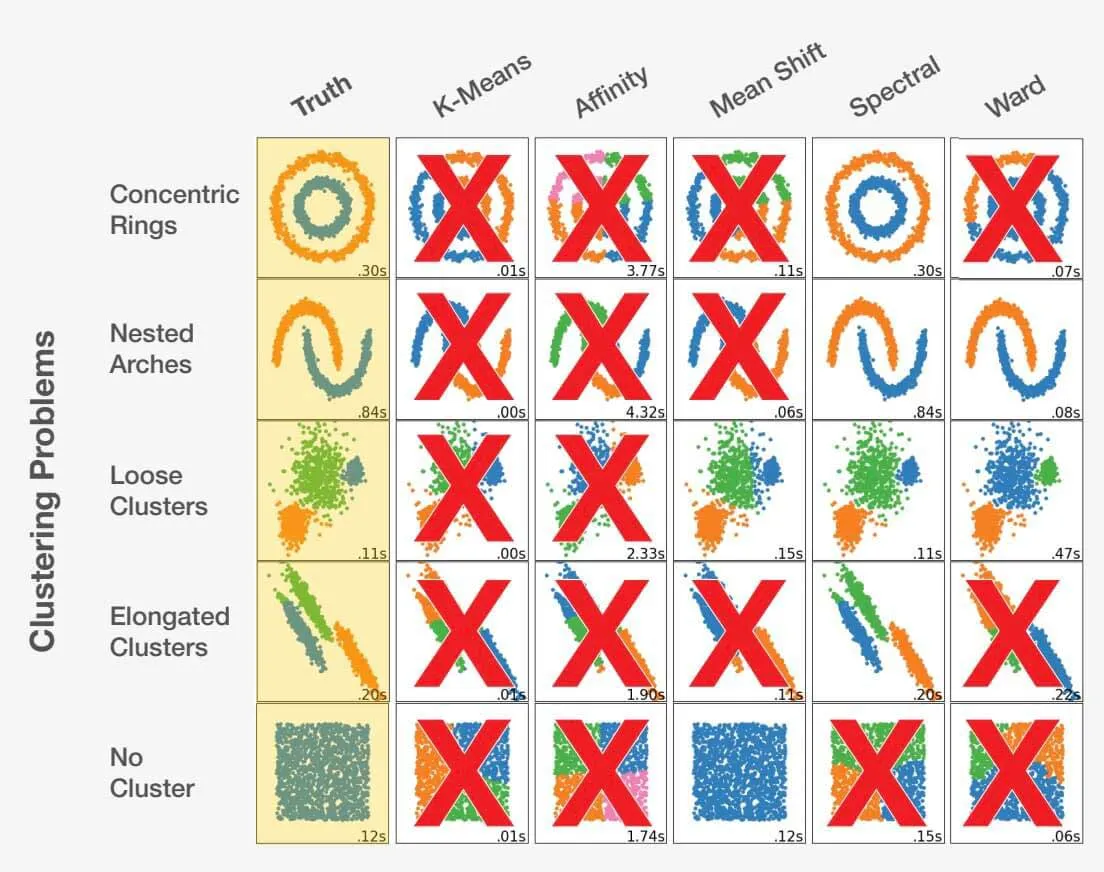
Adaptado de scikit-learn.org.
Elegir el algoritmo adecuado para un conjunto de datos puede influir significativamente en los resultados obtenidos. Cada problema tiene una elección de algoritmo óptima, pero lo más importante es que ciertas elecciones pueden conducir a resultados desfavorables. Esto pone de relieve la importancia crítica de seleccionar el enfoque adecuado para cada problema específico.
¿Cómo medir el éxito de un algoritmo?
Elegir el modelo adecuado como científico de datos implica algo más que precisión. Aunque la precisión es importante, a veces puede ocultar el verdadero rendimiento de un modelo.

Consideremos un problema de clasificación con dos etiquetas, A y B. Si es mucho más probable que se produzca la etiqueta A que la B, un modelo puede lograr una gran precisión eligiendo siempre la etiqueta A. Sin embargo, esto significa que nunca identificará correctamente nada como etiqueta B. Así que la precisión por sí sola no es suficiente si queremos encontrar casos B. Afortunadamente, los científicos de datos disponen de otras métricas que ayudan a optimizar y medir la eficacia del modelo. Afortunadamente, los científicos de datos disponen de otras métricas para ayudar a optimizar y medir la eficacia de un modelo.
Una de estas métricas es la precisión, que mide el grado de acierto de un modelo a la hora de adivinar una etiqueta concreta en relación con el número total de conjeturas. Los científicos de datos que aspiran a una alta precisión construirán modelos que eviten generar falsas alarmas.

Pero la precisión sólo nos cuenta una parte de la historia. No revela si el modelo no identifica casos que son importantes para nosotros. Aquí es donde entra en juego la recuperación. Recall mide la frecuencia con la que un modelo encuentra correctamente una etiqueta concreta en relación con todos los casos de esa etiqueta. Los científicos de datos que busquen una alta recuperación construirán modelos que no pasen por alto casos importantes.

Mediante el seguimiento y el equilibrio de la precisión y la recuperación, los científicos de datos pueden medir y optimizar eficazmente el éxito de sus modelos.